
یادگیری عمیق برای بینایی کامپیوتر

بینایی کامپیوتر (CV) یک حوزه علمی است که نحوه تفسیر ماشینها از معنای تصاویر و فیلمها را تعریف میکند. الگوریتمهای بینایی کامپیوتری...
یادگیری عمیق برای بینایی کامپیوتر
بینایی کامپیوتر (CV) یک حوزه علمی است که نحوه تفسیر ماشینها از معنای تصاویر و فیلمها را تعریف میکند. الگوریتمهای بینایی کامپیوتری معیارهای خاصی را در تصاویر و ویدئوها تجزیه و تحلیل میکنند و سپس از این تفسیرها را برای کارهای پیشبینی یا تصمیمگیری استفاده میکنند.
امروزه بیشتر از تکنیک های یادگیری عمیق برای بینایی کامپیوتری استفاده می شود. این مقاله روش های مختلفی را برای استفاده از یادگیری عمیق در حوزه بینایی کامپیوتر بررسی می کند. به طور خاص، شما با مزایای استفاده از شبکه های عصبی کانولوشن (CNN)، که یک معماری چند لایه ای است و به شبکه های عصبی اجازه می دهد تا بر روی مرتبط ترین ویژگی های تصویر تمرکز کنند، آشنا می شوید.
در این مقاله شما در مورد موارد زیر خواهید آموخت:
بینایی کامپیوتری چیست؟
معماری های یادگیری عمیق برای بینایی کامپیوتری
استفاده از یادگیری عمیق در بینایی کامپیوتر
بینایی کامپیوتر (CV) چیست؟
بینایی کامپیوتر حوزه ای از یادگیری ماشین است که به تفسیر و درک تصاویر و ویدئوها اختصاص داده شده است. از بینایی کامپیوتری می توان برای کمک به آموزش کامپیوتر برای “دیدن” و استفاده از اطلاعات تصویری به منظور انجام کارهای بصری که انسان ها می توانند آن را انجام دهند بهره گرفته می شود.
مدلهای بینایی کامپیوتری برای تفسیر دادههای تصویری بر اساس ویژگیها و اطلاعات متنی شناساییشده در طول فرایند آموزش طراحی شدهاند. این مدل ها این امکان را فراهم می کنند که بتوان تصاویر و ویدیوها را تفسیر کرد و از آن تفاسیر را برای کارهای پیشبینی یا تصمیمگیری استفاده نمود.
بینایی کامپیوتر و پردازش تصویر با وجود اینکه هر دو مرتبط با داده های تصویری هستند اما به یک مفهوم اشاره نمی کنند. پردازش تصویر شامل اصلاح یا بهبود تصاویر برای ایجاد یک نتیجه جدید است. این امر می تواند شامل بهینه سازی روشنایی یا کنتراست، افزایش وضوح، محو کردن اطلاعات حساس یا برش باشد. تفاوت بین پردازش تصویر و بینایی کامپیوتر این است که در پردازش تصویر ضرورتی برای شناسایی محتوا وجود ندارد.
شبکههای عصبی کانولوشن: پایه بینایی کامپیوتری مدرن
الگوریتمهای بینایی کامپیوتری مدرن مبتنی بر شبکههای عصبی کانولوشنال (CNN) هستند که در مقایسه با الگوریتمهای پردازش تصویر سنتی، بهبود چشمگیری را در عملکرد ارائه میدهند.
CNN ها شبکه های عصبی با معماری چند لایه هستند که برای کاهش تدریجی داده ها و محاسبه مرتبط ترین مجموعه استفاده می شوند. سپس این مجموعه با داده های شناخته شده مقایسه می شود تا ورودی داده را شناسایی یا طبقه بندی کند.
CNN ها معمولاً برای انجام وظایف بینایی کامپیوتری استفاده می شوند، با این وجود انجام وظایفی مثل تجزیه و تحلیل متن و تجزیه و تحلیل صوتی نیز قابل انجام است. یکی از اولین معماری های CNN ،AlexNet است (که در ادامه به آن خواهیم پرداخت). این معماری در سال 2012 برنده چالش تشخیص تصویری ImageNet شد.
CNN چگونه کار می کند
هنگامی که یک تصویر با CNN پردازش می شود هر رنگ اصلی استفاده شده در تصویر (آبی، سبز، قرمز) با یک ماتریس مقادیر نشان داده می شود. این مقادیر ارزیابی شده در تنسورهای سه بعدی (در صورتی که تصاویر رنگی باشد) قرار می گیرند که مجموعه ای از پشته های نقشه های ویژگی هستند که به بخشی از تصویر متصل شده اند. این تنسورها با عبور دادن تصویر از میان یک سری لایههای کانولوشنال و ادغام ایجاد میشوند که برای استخراج مرتبطترین دادهها از یک قطعه تصویر و فشرده سازی آن در یک ماتریس کوچکتر و متناظر استفاده میشوند. این فرایند چندین مرتبه تکرار می شود (وابسته به تعداد لایه های کانولوشن در معماری). ویژگی های استخراج شده در فرایند کانولوشن به یک لایه کاملا متصل fully connected ارسال می شوند که پیش بینی ها را تولید می کند.
معماری های یادگیری عمیق برای بینایی کامپیوتر
کارایی و عملکرد یک CNN توسط معماری اش تعیین می شود. این موضوع شامل ساختار لایه ها، نحوه طراحی عناصر و اینکه چه عناصری در چه لایه ای قرار دارند می شود. CNNs های زیادی ایجاد شده اند ولی موارد زیر جزو موثر ترین طراحی ها هستند.
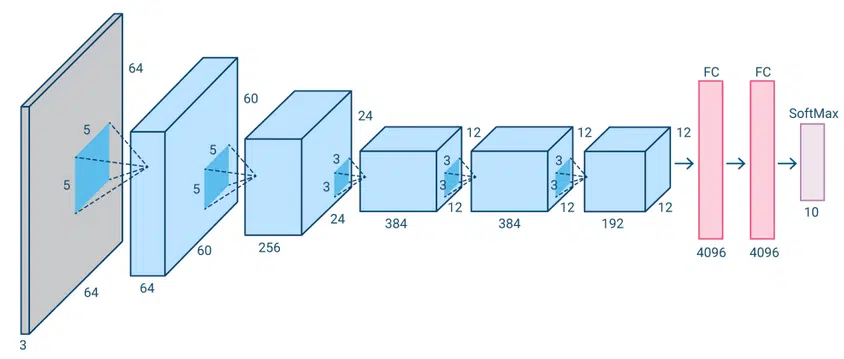
AlexNet (2012)
AlexNet یک معماری بر پایه معماری پیشین LeNet است این معماری دارای پنج لایه کانولوشن و سه لایه کاملا متصل است. AlexNet از یک ساختار سلسله مراتبی دوگانه استفاده می کند که از دوGPU در آموزش بهره می برد.
تفاوت اصلی بین AlexNet و معماری های پیشین استفاده آن از واحد خطی اصلا شده ReLU به جای توابع فعالساز sigmoid یا Tanh است که در شبکه های عصبی سنتی استفاده شده است. ReLU برای محاسبات ساده تر و سریع تر است و این امر AlexNet را قادر می سازد تا مدل ها را سریع تر آموزش دهد.
GoogleNet (2014)
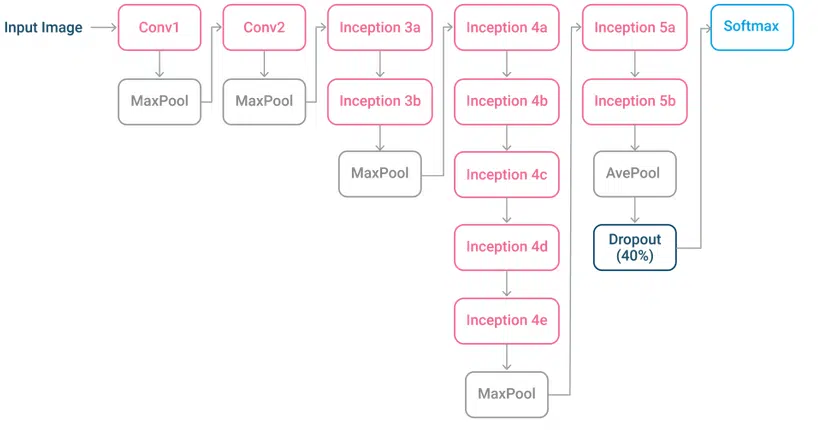
GoogleNet که با عنوان Inception V1 شناخته می شود بر اساس معماری LeNet است. این معماری از ۲۲ لایه تشکیل شده است که دارای گروه های کوچک کانولوشن بوده که ماژول های inception نامیده می شوند. این ماژول های inception از دسته نرمالسازی و RMSprop استفاده می کنند تا تعداد پارامترهای مورد نیاز GoogleNet را برای پردازش کاهش دهند. RMSprop یک الگوریتم است که از روشهای یادگیری تطبیقی استفاده می کند.
VGGNet (2014)
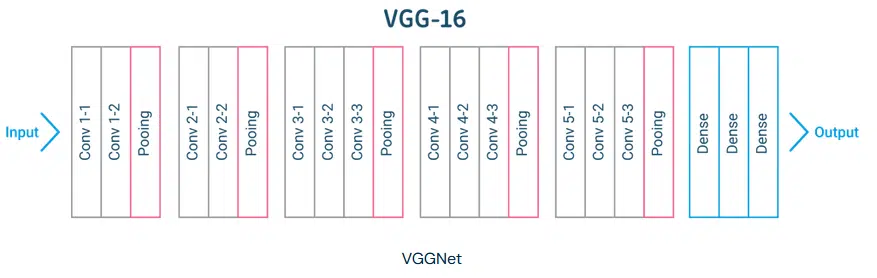
VGG 16 یک معماری ۱۶ لایه ای است (برخی از نسخه ها ۱۹ لایه داشتند). VGGNet دارای لایه های کانولوشن، یک لایه pooling، لایهی کانولوشن بیشتر، لایه pooling تعداد لایه های کانولولوشن دیگر و به همین ترتیب است.
VGG براساس مفهوم یک شبکه بسیار عمیق تر و با فیلترهای کوچکتر است. VGG از کانولوشن های ۳ در ۳ که کوچکترین اندازه فیلتر کانولوشن است و تنها پیکسل های همسایه را بررسی می کند. VGG به دلیل پارامترهای کمتر از فیلترهای کوچکتر که این امر این قابلیت را فراهم می کند تا لایه های بیشتری اضافه شود. این معماری کارایی یکسانی با زمانی که شما یک لایه کانولوشنی ۷ در ۷ داشته باشید.
ResNet (2015)
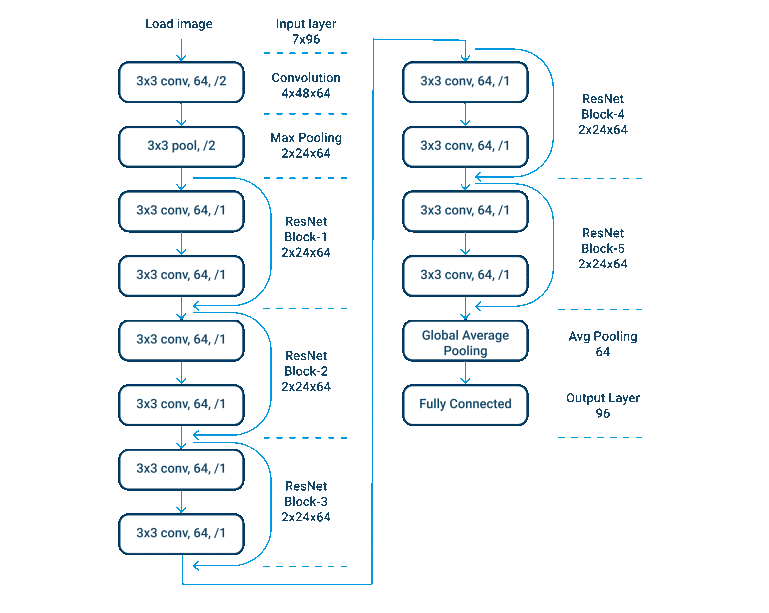
ResNet که مخفف Residual Neural Network است یک معماری است که برای داشتن لایه های زیاد ساخته شده است بازه های معماری استفاده شده معمولا از ResNet-18 (با ۱۸ لایه) تا ResNet-1202 (با ۱۲۰۲ لایه) استفاده می کند. این لایه ها واحد های دروازه های یا اتصالات آماده سازی شده اند. ResNet از دسته بندی نرمالسازی برای بهبود ثبات شبکه استفاده کرده است.
Xception (2016)
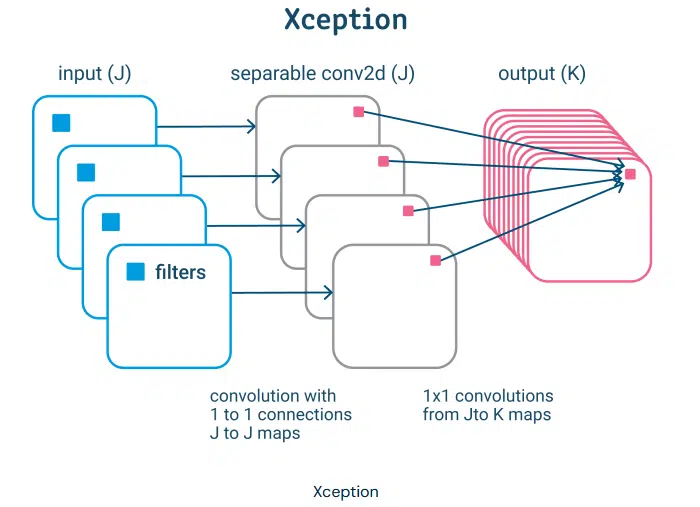
Xception یک معماری بر اساس Inception است. که ماژول Inception را با کانولوشن های عمیق قابل تفکیک جایگزین می کند (کانولوشن عمیق و به دنبال آن کانولوشن های نقطه ای). Xception بدین صورت کار می کند که در ابتدا همبستگی های نقشه بین ویژگی ها و سپس همبستگی های فضایی را بدست می آورد. این امر استفاده موثر تر از پارامترهای مدل را فراهم می کند.
ResNeXt-50 (2017)
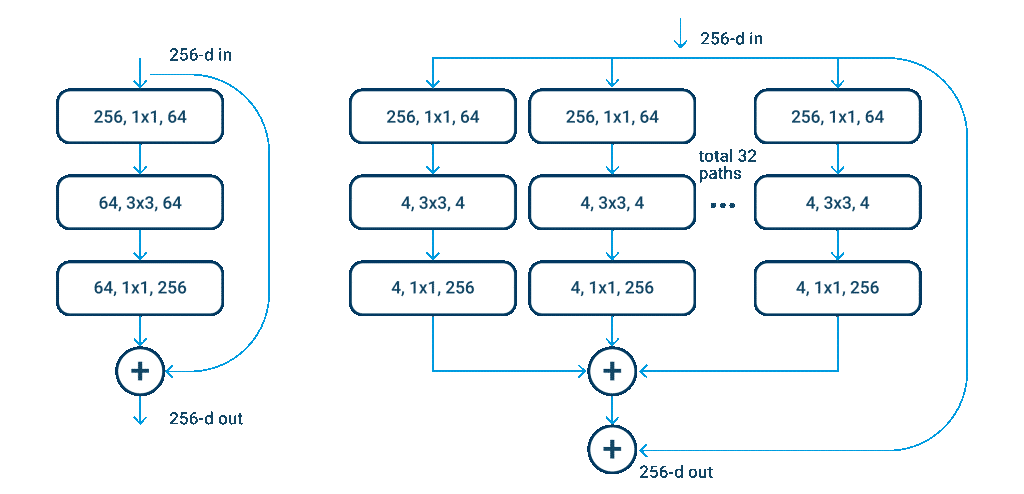
ResNeXt-50 یک معماری بر پایه ی ماژول با ۳۲ راه موازی است. این معماری از کاردینالیتی برای کاهش خطاهای اعتبارسنجی و یک نمایش ساده سازی شده از ماژول های Inception که در معماری های دیگه اضافه شده، استفاده می کند.
کاربردهای یادگیری عمیق در بینایی کامپیوتر
توسعه فن آوری های یادگیری عمیق امکان ایجاد مدل های بینایی کامپیوتری دقیق تر و پیچیده تر را فراهم کرده است. با افزایش این فناوری ها، ادغام برنامه های کاربردی بینایی کامپیوتری موثرتر می شود. در ادامه چندین روش استفاده از یادگیری عمیق برای بهبود بینایی کامپیوتر آورده شده است.
تشخیص شی
دو نوع رایج تشخیص شی وجود دارد که از طریق تکنیکهای بینایی کامپیوتری انجام میشود:
1) تشخیص شی دو مرحله ای
اولین گام به یک شبکه پیشنهاد دهنده ی ناحیه (RPN) نیاز دارد که تعدادی ناحیه پیشنهادی را که ممکن است دارای اشیا مهم باشند را فراهم می کند. مرحله دوم، انتقال ناحیه های پیشنهادی به یک معماری طبقهبندی عصبی که معمولاً یک الگوریتم گروهبندی سلسله مراتبی مبتنی بر RCNN است، یا ادغام ناحیه مورد علاقه (ROI) در Fast RCNN است. این رویکردها کاملاً دقیق هستند، اما می توانند بسیار کند عمل کنند.
2) تشخیص اشیا یک مرحله ای
با توجه به نیاز به تشخیص واقعی اشیا، معماریهای تک مرحلهای تشخیص اشیا مانند YOLO ،SSD و RetinaNet بوجود آمده اند. این معماری ها مرحله تشخیص و طبقهبندی را با پیشبینیهای کادر مرزی و رگرسیون ترکیب میکنند. هر کادر مرزی تنها با چند مختصات نشان داده می شود که ترکیب مرحله تشخیص و طبقه بندی را آسان تر کرده و به پردازش سرعت می بخشد.
مکان یابی و تشخیص شی
مکان یابی تصویر برای تعیین محل قرارگیری اشیاء در یک تصویر استفاده می شود. پس از شناسایی شدن، اشیا با یک کادر محدود مشخص می شوند. تشخیص شیء کار را گسترش داده و اشیاء شناسایی شده را طبقه بندی می کند. این فرآیند بر اساس CNN هایی مانند AlexNet ،Fast RCNN و Faster RCNN صورت می پذیرد. مکان یابی و تشخیص شی می تواند برای شناسایی چندین شی در صحنه های پیچیده استفاده شود. مکان یابی می تواند برای عملکردهایی مانند تفسیر تصاویر تشخیصی در پزشکی اعمال شود.
قطعه بندی معنایی
قطعه بندی معنایی، که به عنوان قطعه بندی شی نیز شناخته می شود، مشابه با تشخیص شی است با این تفاوت که بر اساس پیکسل های خاص مربوط به یک شی عمل می کند. قطعه بندی معنایی توانایی را فراهم می کند که اشیاء تصویر با صحت بیشتری تعریف شده و نیازی به کادرهای محدود کننده نداشته باشند. قطعه بندی معنایی اغلب با استفاده از شبکه های کاملاً کانولوشنال (FCN) یا U-Nets انجام می شود.
یکی از کاربردهای رایج برای قطعه بندی معنایی، آموزش وسایل نقلیه خودران است. با این روش، محققان میتوانند از تصاویر خیابانها یا معابر با مرزهای دقیق تعریف شده برای اشیا استفاده کنند.
تخمین موقعیت
تخمین موقعیت یک متد است که برای تشخیص نقاط متصل در تصاویر یک فرد یا یک شی و اینکه این نقاط متصل چه چیزی را نشان می دهند استفاده می شود. از تخمین موقعیت می توان در تصاویر دو بعدی و سه بعدی استفاده نمود. معماری اصلی استفاده شده در تخمین موقعیت PoseNet بوده که بر پایه CNN است.
تخمین موقعیت برای تعیین بخش هایی از بدن که ممکن است در یک تصویر نشان داده شود استفاده می شود و می توان از آن برای ایجاد موقعیت های واقعی یا حرکت چهره های انسانی استفاده کرد. اغلب از این قابلیت برای واقعیت افزوده، انعکاس حرکات با روباتیک یا تجزیه و تحلیل راه رفتن استفاده می شود.
درباره یادگیری عمیق برای بینایی کامپیوتر بیشتر بدانید:
TensorFlow CNN
شبکههای عصبی کانولوشنال (CNN)، یک تکنیک کلیدی در یادگیری عمیق برای بینایی کامپیوتری است که هنوز برای عموم مردم ناشناخته است، با این وجود CNN هسته اصلی بسیاری از نوآوریهای بزرگ است که می توان برای مثال به باز کردن قفل تلفن همراه با تشخیص چهره یا وسایل نقلیه ایمن خود ران اشاره نمود.
یک دید کلی در مورد TensorFlow CNN بدست آورید و به سرعت آموزش دیده تا اولین CNN خود را در TensorFlow با استفاده از مجموعه داده MNIST-Fashion ایجاد کنید.
برای اطلاعات بیشتر به این آدرس مراجعه فرمایید.
PyTorch ResNet: اصول اولیه و یک آموزش سریع
ResNets یک معماری شبکه عصبی رایج است که برای برنامه های بینایی کامپیوتری یادگیری عمیق مانند تشخیص اشیا و قطعه بندی تصویر استفاده می شود. با مراجعه به این آدرس با اصول اولیه معماری شبکه عصبی ResNet آشنا شوید و ببینید که چگونه ResNet از پیش آموزش دیده و سفارشی شده را در PyTorch با نمونه کد اجرا کنید.
درک شبکه های عصبی کانولوشن عمیق
یادگیری عمیق یک تکنیک یادگیری ماشین است که برای ساخت سیستم های هوش مصنوعی (AI) استفاده می شود. شبکه های عصبی کانولوشن عمیق مبتنی بر ایده شبکه های عصبی مصنوعی (ANN) است که برای انجام تجزیه و تحلیل پیچیده مقادیر زیادی از داده ها با عبور دادن آن از لایه های متعدد نورون طراحی شده است.
با مراجعه با این آدرس با مفهوم شبکههای عصبی کانولوشنال عمیق (CNN یا DCNN)، انواع آن ها و این که این شبکهها برای چه کاربردهای تجاری مناسبتر هستند آشنا شوید.
PyTorch CNN: مبانی و یک آموزش سریع
PyTorch یک چارچوب پایتون برای یادگیری عمیق است که انجام پروژه های تحقیقاتی را آسان می کند و از سخت افزار CPU یا GPU استفاده می کند. واحد منطقی اصلی در PyTorch یک تنسور، یک آرایه چند بعدی است. PyTorch تعداد زیادی تنسور را در نمودارهای محاسباتی ترکیب می کند و از آنها برای ساخت، آموزش و اجرای معماری شبکه های عصبی استفاده می کند.
با مراجعه به این آدرس درباره PyTorch، در مورد نحوه عملکرد شبکه های عصبی کانولوشنال بیاموزید، و یک آموزش سریع برای ساخت یک CNN ساده در PyTorch را فرا گرفته و ارزیابی نتایج را انجام دهید.
PyTorch GAN: درک GAN و کدگذاری آن در PyTorch
شبکه مولد تخاصمی (GAN) از دو شبکه عصبی استفاده می کند که مولد و تفکیک کننده نام دارند تا داده های مصنوعی را ایجاد کند. برای مثال معماری های GAN می توانند تصاویر غیر واقعی از انسان ها و حیوانات ایجاد کنند. با مراجعه به این آدرس در مورد شبکه مولد تخاصمی (GAN) و نحوه کدنویسی آن بیشتر بیاموزید.
آموزش توزیع شده چیست و چگونه می تواند ارزشمند باشد
آموزش مدل های یادگیری عمیق زمان بر است. شبکههای عصبی عمیق اغلب از میلیونها یا میلیاردها پارامتر تشکیل شدهاند که روی مجموعه دادههای حجیم آموزش داده میشوند. با پیچیدهتر شدن مدلهای یادگیری عمیق، زمان محاسبات میتواند بیشتر شده و آموزش یک مدل روی یک GPU ممکن است هفته ها طول بکشد.
با مراجعه به این آدرس نگاهی عمیق تر به آموزش توزیعشده و چگونگی سرعت بخشیدن به فرآیند آموزش مدلهای یادگیری عمیق در پردازندههای گرافیکی داشته باشید.





