
تشخیص کلاهبرداری کارت اعتباری با استفاده از خوشهبندی طیفی

در عصر دیجیتال امروز، کلاهبرداری با کارت اعتباری (شکل 1) به یک نگرانی جدی برای مصرفکنندگان و مؤسسات مالی تبدیل شده است. امروزه با افزایش...
در این آموزش، یاد خواهید گرفت که چگونه از خوشهبندی طیفی برای تشخیص تقلب (کلاهبرداری) استفاده کنید.

در عصر دیجیتال امروز، کلاهبرداری با کارت اعتباری (شکل 1) به یک نگرانی جدی برای مصرفکنندگان و مؤسسات مالی تبدیل شده است. امروزه با افزایش حجم تراکنشهای آنلاین، نیاز به سیستمهای تشخیص تقلب قوی و کارآمد بیش از هر زمان دیگری ضروری است. روشهای سنتی اغلب در شناسایی کلاهبرداری پیچیده ناکام میمانند، بنابراین بررسی تکنیکهای پیشرفته امری ضروری است.

یکی از رویکردهای امیدوارکننده در این حوزه تشخیص ناهنجاری است که بر شناسایی الگوهای غیرمعمول خارج از عرف تمرکز دارد. با استفاده از تشخیص ناهنجاری، میتوانیم بینظمیهای پنهان در دادههای تراکنش را که ممکن است نشاندهنده کلاهبرداری باشند را کشف کنیم. خوشهبندی طیفی، یک تکنیک است که ریشه در نظریه گراف دارد و یک روش منحصر به فرد برای تشخیص ناهنجاریها با تبدیل دادهها به یک گراف و تجزیه و تحلیل خواص طیفی آن ارائه میدهد. این روش در شناسایی خوشههای تراکنشهای مشابه و جدا کردن آنهایی که از عرف تراکنش ها منحرف میشوند، برتری دارد. در این آموزش، به اصول تشخیص ناهنجاری خواهیم پرداخت و درک خواهیم کرد که چگونه از خوشهبندی طیفی برای تشخیص تقلب کارت اعتباری استفاده میشود.
درک تشخیص ناهنجاری: مفاهیم، انواع و الگوریتمها
تشخیص ناهنجاری چیست؟
تشخیص ناهنجاری (شکل 2) یک تکنیک حیاتی در تحلیل دادهها است که برای شناسایی نقاط داده، رویدادها یا مشاهداتی که به طور قابل توجهی از هنجار منحرف میشوند، استفاده میشود. این انحرافها، که به عنوان ناهنجاریها یا داده های پرت شناخته میشوند، میتوانند اطلاعات مهم و اغلب قابل اقدام (مانند تقلب، نفوذ به شبکه یا خرابی سیستم) را نشان دهند.
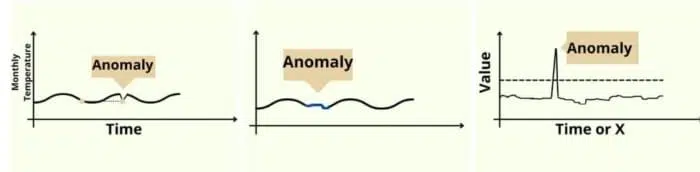
هدف اصلی تشخیص ناهنجاری، تمایز بین الگوهای طبیعی و غیرطبیعی در یک مجموعه داده است که امکان مداخله به موقع و کاهش خطرات بالقوه را فراهم میکند.
کاربردهای تشخیص ناهنجاری
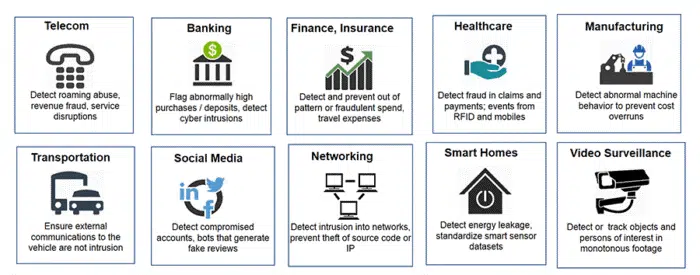
شکل 3 چندین کاربرد تشخیص ناهنجاری در زمینههای مختلف را شرح میدهد. به عنوان مثال:
تشخیص کلاهبرداری کارت اعتباری:
در زمینه تراکنشهای کارت اعتباری، تشخیص ناهنجاری میتواند برای شناسایی فعالیتهای کلاهبردارانه استفاده شود. به عنوان مثال، اگر یک کارت اعتباری ناگهان برای انجام یک خرید بزرگ در یک کشور خارجی استفاده شود، این تراکنش ممکن است به عنوان یک ناهنجاری علامتگذاری شود. با تجزیه و تحلیل الگوهای تراکنشهای عادی، سیستم میتواند فعالیتهای غیرمعمول را که از هنجار منحرف میشوند، تشخیص دهد.
تشخیص نفوذ به شبکه:
در امنیت سایبری، تشخیص ناهنجاری برای شناسایی نفوذهای بالقوه به شبکه استفاده میشود. به عنوان مثال، اگر کاربری که معمولاً در ساعات کاری به شبکه دسترسی دارد، ناگهان در نیمهشب وارد سیستم شود و شروع به دانلود مقادیر زیادی از دادهها کند، این رفتار به عنوان ناهنجاری در نظر گرفته خواهد شد. سپس سیستم میتواند به مدیران برای بررسی بیشتر هشدار دهد.
نظارت بر تجهیزات صنعتی یا نگهداری پیشبینیکننده:
در محیطهای صنعتی، تشخیص ناهنجاری میتواند برای نظارت بر تجهیزات برای خرابیهای بالقوه استفاده شود. به عنوان مثال، اگر یک دستگاه که معمولاً در محدوده دمای مشخصی کار میکند، ناگهان افزایش دما را نشان دهد، این امر میتواند نشاندهنده نقص فنی باشد. تشخیص زودهنگام چنین ناهنجاریهایی میتواند از خرابیها و تعمیرات پرهزینه جلوگیری کند.
انواع مشکلات تشخیص ناهنجاری
مشکلات تشخیص ناهنجاری میتوانند به طور کلی به سه نوع اصلی طبقهبندی شوند:
- ناهنجاریهای نقطهای
- ناهنجاریهای زمینهای
- ناهنجاریهای جمعی
هر نوع تصویر (شکل 4) دارای ویژگیها و کاربردهای متمایز است، بنابراین درک تفاوتهای آنها و نحوه شناسایی مؤثر آنها ضروری است.

ناهنجاریهای نقطهای
ناهنجاریهای نقطهای، که همچنین به عنوان ناهنجاریهای جهانی شناخته میشوند، زمانی رخ میدهند که یک نقطه داده فردی به طور قابل توجهی از بقیه دادهها منحرف میشود. این ناهنجاریها سادهترین تشخیص هستند زیرا به وضوح در پسزمینه دادههای عادی برجسته میشوند. به عنوان مثال، یک تراکنش واحد که بسیار بزرگتر از معمول است یا در یک مکان غیرمعمول رخ میدهد، میتواند به عنوان یک ناهنجاری نقطهای علامتگذاری شود.
ناهنجاریهای زمینهای
ناهنجاریهای زمینهای، که همچنین به عنوان ناهنجاریهای شرطی شناخته میشوند، زمانی رخ میدهند که یک نقطه داده در یک زمینه خاص ناهنجاری در نظر گرفته شود، اما ممکن است در زمینه دیگر عادی باشد. زمینه توسط نقاط داده اطراف یا ویژگیهای زمینهای اضافی تعریف میشود. به عنوان مثال، یک دمای بالا ممکن است در طول روز طبیعی باشد، اما در شب ناهنجاری در نظر گرفته شود. زمینه در اینجا زمان روز است.
ناهنجاریهای جمعی
ناهنجاریهای جمعی زمانی رخ میدهند که مجموعهای از نقاط داده مرتبط ناهنجار باشند، حتی اگر نقاط فردی درون مجموعه ناهنجار نباشند. این ناهنجاریها بر اساس رابطه بین نقاط داده شناسایی میشوند، نه بر اساس مقادیر آنها. به عنوان مثال، یک سری بسته داده کوچک که در یک دوره کوتاه ارسال میشوند ممکن است به طور جداگانه طبیعی باشند، اما به طور جمعی، میتوانند نشاندهنده یک حمله انکار سرویس (DoS) باشند.
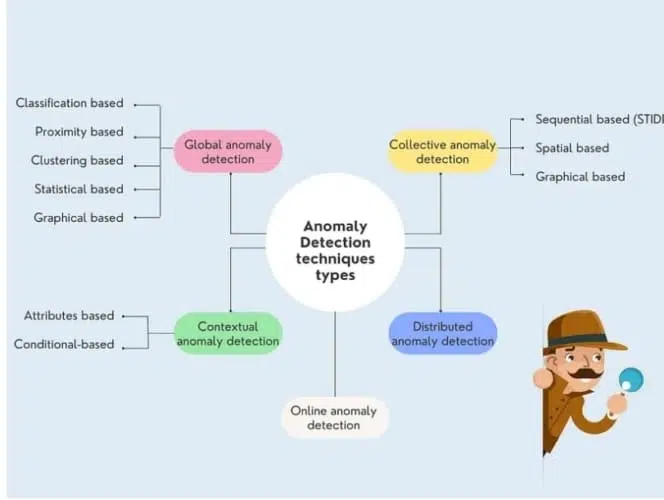
الگوریتمهای تشخیص ناهنجاری
میتوانیم الگوریتمهای تشخیص ناهنجاری (شکل 5) را به موارد زیر تقسیم کنیم:
- روشهای آماری
- روشهای یادگیری ماشین
- روشهای مبتنی بر نزدیکی
- روشهای گروهی
روشهای آماری
روشهای آماری بر این فرض استوار هستند که نقاط داده عادی از یک توزیع آماری خاص پیروی میکنند. ناهنجاریها به عنوان نقاط دادهای که به طور قابل توجهی از این توزیع منحرف میشوند، شناسایی میشوند. به عنوان مثال، روش Z-Score که درشکل 6 قابل مشاهده است مقادیر Z-score را برای هر نقطه داده محاسبه میکند که اندازهگیری میکند چند انحراف استاندارد یک نقطه از میانگین فاصله دارد. نقاط دادهای با Z-score بالاتر از یک آستانه خاص به عنوان ناهنجاری در نظر گرفته میشوند.
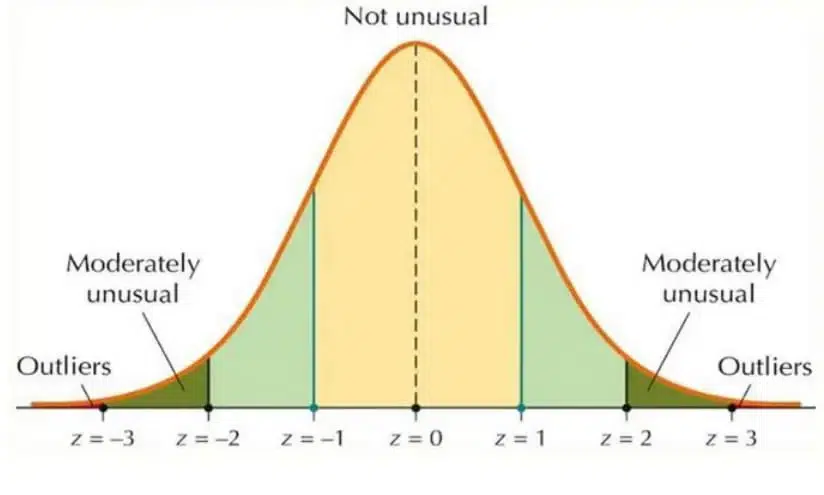
چنین روشی میتواند در سناریوهایی (مانند تراکنشهای کارت اعتباری) قابل اجرا باشد که در آن تراکنشی با Z-score مقدار 5 ممکن است به عنوان یک ناهنجاری علامتگذاری شود زیرا از مقدار متوسط تراکنش فاصله زیادی دارد.
روشهای یادگیری ماشین
روشهای یادگیری ماشین (شکل 7) میتوانند به تکنیکهای نظارتشده، نظارتنشده و نیمهنظارتشده تقسیم شوند.
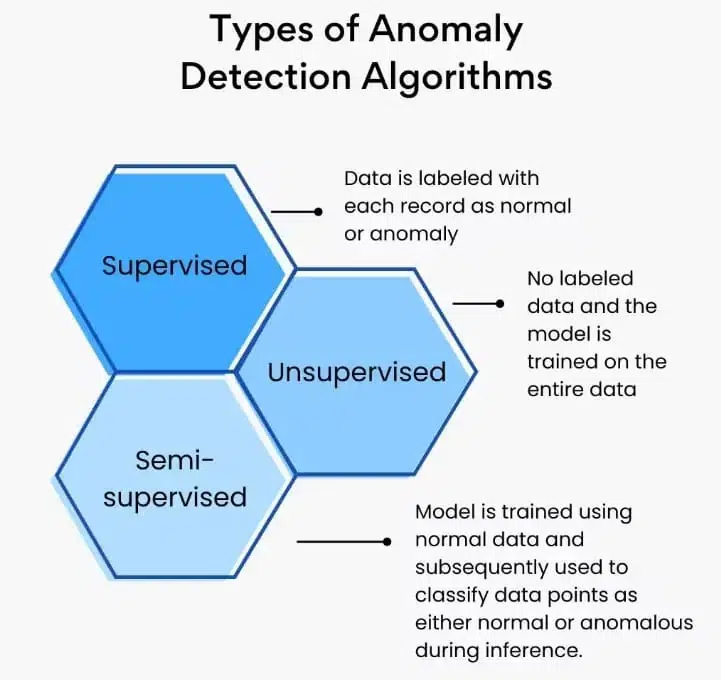
یادگیری نظارتشده
این روشها به دادههای برچسبگذاری شده برای آموزش مدل نیاز دارند. مدل یاد میگیرد تا بین نقاط داده طبیعی و غیرطبیعی تمایز قائل شود.
به عنوان مثال، در تشخیص کلاهبرداری، SVM (ماشین بردار پشتیبان) میتواند تراکنشها را بر اساس دادههای برچسبگذاری شده تاریخی به عنوان تقلبی یا غیرتقلبی طبقهبندی کند.
به طور مشابه، تکنیکهای شبکه عصبی مانند شبکههای عصبی کانولوشنال (CNNs) و شبکههای عصبی بازگشتی (RNNs) میتوانند برای دادههای تصویر و سری زمانی برای تشخیص نقص در محصولات با یادگیری از تصاویر برچسبگذاری شده محصولات معیوب و غیرمعیوب استفاده شوند.
یادگیری نظارتنشده
این روشها به دادههای برچسبگذاری شده نیاز ندارند و میتوانند ناهنجاریها را بر اساس ساختار ذاتی دادهها شناسایی کنند.
به عنوان مثال، الگوریتمهای خوشهبندی مانند K-Means، خوشهبندی طیفی و DBSCAN خوشهبندی فضایی مبتنی بر چگالی کاربردها با نویز برای تقسیم دادهها به خوشهها استفاده میشوند. نقاط دادهای که متعلق به هیچ خوشهای نیستند یا از مرکز خوشهها فاصله زیادی دارند، به عنوان ناهنجاری در نظر گرفته میشوند.
به عنوان مثال، در بخشبندی مشتری، خوشهبندی K-means میتواند مشتریانی را شناسایی کند که رفتار خرید آنها به طور قابل توجهی با اکثریت متفاوت است.
یادگیری نیمهنظارتشده
این روشها از مقدار کمی داده برچسبگذاری شده برای هدایت فرآیند یادگیری استفاده میکنند.
به عنوان مثال، در امنیت شبکه، One-Class SVM میتواند فقط بر روی دادههای ترافیک عادی آموزش داده شود و برای شناسایی ناهنجاریهای نقطهای (مانند الگوهای غیرمعمول ترافیک شبکه) استفاده شود.
به طور مشابه، خودرمزنگارها میتوانند برای بازسازی دادههای ورودی آموزش داده شوند و نقاط دادهای با خطاهای بازسازی بالا میتوانند به عنوان ناهنجاریها علامتگذاری شوند.
روشهای مبتنی بر نزدیکی
روشهای مبتنی بر نزدیکی میتوانند ناهنجاریها را بر اساس فاصله بین نقاط داده تشخیص دهند. به عنوان مثال، الگوریتم K-Nearest Neighbors میتواند تلاشهای ورود غیرمعمول را بر اساس فاصله با الگوهای ورود معمولی شناسایی کند.
الگوریتم Local Outlier Factor (LOF) انحراف چگالی محلی یک نقطه داده را نسبت به همسایگان آن اندازهگیری میکند. نقاطی با چگالی به طور قابل توجهی کمتر از همسایگان خود به عنوان ناهنجاری در نظر گرفته میشوند.





