
معرفی جامع TensorRT برای مبتدیان و توسعهدهندگان میانردهی هوش مصنوعی

TensorRT یک بسته نرمافزاری (SDK) برای اجرای سریع مدلهای یادگیری عمیق روی کارتهای گرافیک NVIDIA است. در عمل، شما مدل خود را در فریمورکی مانند TensorFlow یا PyTorch آموزش میدهید، آن را به یک قالب…
TensorRT یک بسته نرمافزاری (SDK) برای اجرای سریع مدلهای یادگیری عمیق روی کارتهای گرافیک NVIDIA است. در عمل، شما مدل خود را در فریمورکی مانند TensorFlow یا PyTorch آموزش میدهید، آن را به یک قالب میانی (معمولاً ONNX) صادر میکنید، و سپس با TensorRT آن را به یک «موتور» (نمایش بهینه شده برای اجرا) تبدیل میکنید. این بسته نرم افزاری بهینهسازیهای زیادی (مثل تلفیق لایهها، تنظیم کرنلها و محاسبه با دقت مخلوط) انجام میدهد تا حداکثر کارایی و حداقل تأخیر در اجرا را بدون افت محسوس دقت به دست آورد.
به طور خلاصه، TensorRT در مرحلهی استفاده و استقرار مدل وارد میشود: پس از آموزش مدل، TensorRT آن را به یک نسخه بهینه شده برای اجرا روی GPU تبدیل میکند و سرعت اجرای آن را به طور چشمگیری افزایش میدهد. این قابلیت برای کاربردهایی که نیاز به پاسخ آنی یا پردازش پرحجم دارند (مانند خودروهای خودران، تحلیل ویدئو، یا خدمات ابری هوش مصنوعی) بسیار مهم است.
جایگاه در جریان کاری یادگیری ماشین
TensorRT پس از آموزش مدل وارد فرآیند میشود. جریان کاری معمول به این صورت است:
آموزش مدل (مثلاً ResNet یا Transformer) در PyTorch یا TensorFlow → صادرات مدل به فرمت ONNX → استفاده از TensorRT برای تبدیل آن به موتور اجرای سریع روی GPU.
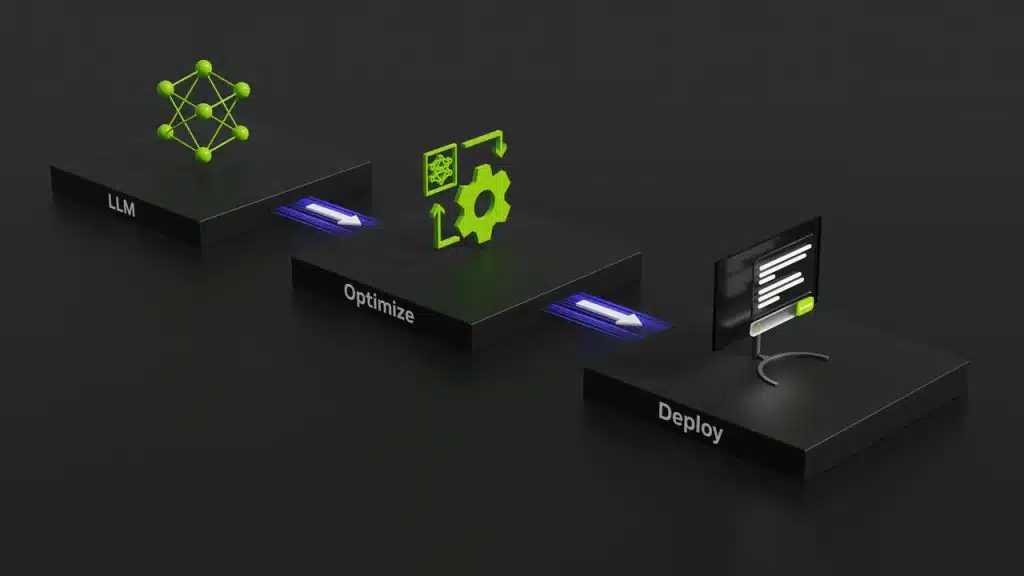
نمودار زیر این جریان را نشان میدهد:
(تصویر: جایگاه TensorRT در جریان کاری استقرار مدل هوش مصنوعی)
در این فرآیند:
-
صادرات مدل: مدل آموزشدیده را به قالب ONNX یا قالبهای پشتیبانی شده صادر میکنیم.
-
انتخاب دقت محاسباتی: بین FP32 (دقت کامل)، FP16 (نیمه دقیق) یا INT8 (صحیح ۸ بیتی) یکی را انتخاب میکنیم.
-
تبدیل مدل: با استفاده از ابزارهای تنسور آر تی، مدل را به موتور بهینه تبدیل میکنیم.
-
استقرار موتور: موتور ساخته شده را در برنامه کاربردی بارگذاری و اجرا میکنیم.
این مراحل هم از طریق ابزارهای خط فرمان مثل trtexec و هم از طریق APIهای Python/C++ قابل انجام است. همچنین کتابخانههایی مانند Torch-TensorRT برای یکپارچهسازی مستقیم با PyTorch وجود دارند.
مفاهیم کلیدی: بهینهسازی، دقت عددی و شتابدهی به استنتاج
قدرت اصلی TensorRT در بهینهسازیهای پیچیده است که قبل از اجرا روی مدل انجام میدهد. مهمترین تکنیکها عبارتند از:
-
تلفیق لایهها: لایههای متوالی مثل Convolution → BatchNorm → ReLU در یک عملیات ترکیب میشوند تا مصرف حافظه و زمان اجرا کاهش یابد.
-
دقت پایینتر (FP16 و INT8): کاهش دقت محاسباتی (مثلاً از ۳۲ بیت به ۱۶ یا ۸ بیت) باعث کاهش حجم حافظه و افزایش سرعت اجرا میشود. FP16 معمولاً بدون افت دقت محسوس سرعت را دو برابر میکند. INT8 سرعت بیشتری دارد ولی نیازمند مرحلهی «کالیبراسیون» است.
-
کالیبراسیون INT8: TensorRT با عبور دادن دادههای نمونه از مدل، محدوده مقادیر را تخمین میزند و مدل را برای اجرا با دقت ۸ بیتی آماده میکند.
-
تنظیم خودکار کرنلها: TensorRT چندین کرنل CUDA را برای هر عملیات آزمایش کرده و سریعترین گزینه را انتخاب میکند.
-
بهینهسازی حافظه و پردازش چندرشتهای: کاهش کپیهای حافظهای و پردازش موازی چند جریان ورودی، به کارایی بالاتر منجر میشود.
در پایان فرآیند، TensorRT یک موتور بهینه شده ایجاد میکند که میتواند تا ۱۰ برابر سریعتر از اجرای اولیه مدل عمل کند (بسته به معماری و دقت انتخاب شده).
استفاده و کاربرد: نمونههای کد
تبدیل مدل با trtexec
سادهترین روش ساخت موتور TensorRT استفاده از ابزار خط فرمان trtexec است:
trtexec --onnx=resnet50/model.onnx --saveEngine=resnet50.engine
این فرمان مدل resnet50 را از قالب ONNX بارگذاری کرده، بهینهسازی میکند و فایل موتور نهایی resnet50.engine را ذخیره میکند.
برای ساخت موتور با دقت FP16:
trtexec --onnx=model.onnx --saveEngine=model_fp16.engine --fp16
و برای ساخت موتور INT8 (با استفاده از فایل کالیبراسیون):
trtexec --onnx=model.onnx --saveEngine=model_int8.engine --int8 --calib=calib.table
اجرای استنتاج در پایتون
پس از ساخت موتور، میتوانید آن را در کد Python بارگذاری و اجرا کنید:
import numpy as np
from onnx_helper import ONNXClassifierWrapper # (کتابخانه فرضی)
# بارگذاری موتور
engine_file = "resnet50.engine"
precision = np.float32 # یا np.float16
trt_model = ONNXClassifierWrapper(engine_file, target_dtype=precision)
# ورودی ساختگی آماده کنید
input_shape = (1, 3, 224, 224)
dummy_input = np.zeros(input_shape, dtype=precision)
# انجام استنتاج
predictions = trt_model.predict(dummy_input)
print("خروجی پیشبینی شده:", predictions.shape)
در برنامههای واقعی، معمولاً با APIهای رسمی TensorRT کار میکنید تا فایل موتور را بارگذاری کنید، زمینه اجرا بسازید، ورودی/خروجیها را متصل کنید و استنتاج را اجرا نمایید.
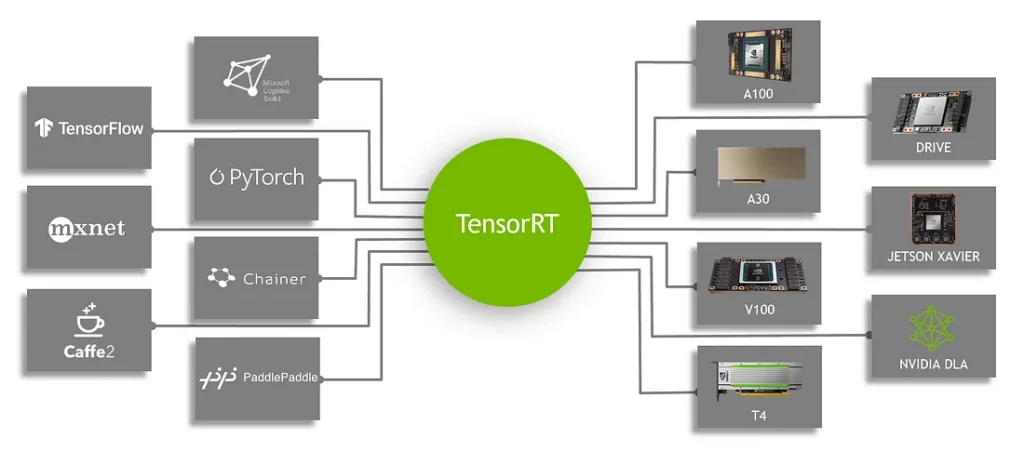
مقایسه با ONNX Runtime و OpenVINO
-
ONNX Runtime: یک چارچوب همهکارهی اجرا برای مدلهای ONNX است. روی CPU، GPU و حتی TensorRT قابل استفاده است. اگر بخواهید مدل را روی سختافزارهای مختلف اجرا کنید (نه فقط کارتهای گرافیک انویدیا)، ONNX Runtime گزینه مناسبی است.
-
OpenVINO: محصول Intel برای استقرار مدلهای یادگیری عمیق روی پردازندههای Intel (و پردازندههای گرافیکی مجتمع) است. این ابزار بهینهسازی بسیار خوبی برای پردازندههای مرکزی انجام میدهد اما از کارتهای گرافیک NVIDIA پشتیبانی نمیکند.
نتیجهگیری: اگر سختافزار شما کارت گرافیک NVIDIA است، TensorRT معمولاً سریعترین عملکرد را ارائه میدهد.
نکات عملی و محدودیتها
-
پشتیبانی از عملیات: همهی لایهها و عملیاتها در TensorRT پشتیبانی نمیشوند. در صورت نیاز، میتوانید افزونه (Plugin) بنویسید.
-
استراتژی انتخاب دقت: پیشنهاد میشود ابتدا مدل را با دقت FP32 تست کنید، سپس به FP16 بروید. اگر افت دقت کمی مشاهده شد، FP16 را استفاده کنید. INT8 نیاز به کالیبراسیون دقیق دارد.
-
اندازهی دسته (Batch Size): برای بهترین سرعت، دستهی دادهها را ثابت کنید. در برخی موارد، افزایش اندازهی دسته باعث بهبود شدید در سرعت میشود.
-
اندازه فضای کاری (Workspace Size): هنگام ساخت موتور، اگر حافظه کم آوردید، باید اندازه Workspace را افزایش دهید.
-
اجرای موازی: اجرای چند جریان استنتاج به طور موازی میتواند باعث استفاده بهتر از GPU و افزایش بازدهی شود.
-
سازگاری سختافزاری: TensorRT فقط روی کارتهای NVIDIA اجرا میشود. برای CPUها باید از OpenVINO یا ONNX Runtime استفاده کنید.
-
نسخهها: گرچه مفاهیم کلی ثابت هستند، اما APIها در نسخههای جدید تغییراتی ممکن است داشته باشند؛ لذا همیشه مستندات بهروز را مطالعه کنید.
منابع پیشنهادی برای ادامه مطالعه
-
مستندات رسمی TensorRT
-
مقالات آموزشی وبلاگ توسعهدهندگان NVIDIA
-
مخزن GitHub مربوطه
-
انجمنهای رسمی انویدیا برای پرسش و پاسخ
خلاصه
تنسورآر تی یک موتور قدرتمند برای بهینهسازی و اجرای مدلهای یادگیری عمیق روی کارتهای گرافیک NVIDIA است. این ابزار از طریق ترکیبی از تکنیکهای بهینهسازی گراف محاسباتی، کاهش دقت عددی، انتخاب کرنلهای بهینه و پردازش موازی، سرعت اجرای مدل را چندین برابر میکند. با رعایت نکات عملی (مثل تست دقت، بهینهسازی حافظه و مدیریت جریانهای داده)، میتوانید به بهترین کارایی در پروژههای یادگیری ماشین خود برسید.





