
یادگیری عمیق برای بینایی کامپیوتر: مدل های ضروری و کاربردهای عملی در دنیای واقعی

پیشرفت بینایی کامپیوتر، زمینه ای که یادگیری ماشین را با علم کامپیوتر ترکیب می کند، با ظهور یادگیری عمیق به طور قابل توجهی ارتقا یافته است...
پیشرفت بینایی کامپیوتر، زمینه ای که یادگیری ماشین را با علم کامپیوتر ترکیب می کند، با ظهور یادگیری عمیق به طور قابل توجهی ارتقا یافته است. این مقاله در مورد یادگیری عمیق برای بینایی کامپیوتر، سفر تحولآفرین از روشهای بینایی رایانهای سنتی به ارتفاعات نوآورانه یادگیری عمیق را بررسی میکند.
ما با مروری بر تکنیک های اساسی مانند آستانه گذاری و تشخیص لبه و نقش حیاتی OpenCV در رویکردهای سنتی شروع می کنیم.
تاریخچه مختصر و تکامل بینایی کامپیوتری سنتی
بینایی کامپیوتر، حوزه ای در تقاطع یادگیری ماشین و علوم کامپیوتر، ریشه در دهه 1960 دارد، زمانی که محققان برای اولین بار تلاش کردند کامپیوترها را قادر به تفسیر داده های بصری کنند. سفر با کارهای ساده ای مانند تشخیص اشکال آغاز شد و به سمت عملکردهای پیچیده تر پیش رفت. نقاط عطف کلیدی شامل توسعه اولین الگوریتم برای پردازش تصویر دیجیتال در اوایل دهه 1970 و متعاقب آن تکامل روشهای تشخیص ویژگی است. این پیشرفتهای اولیه، زمینهای را برای بینایی رایانهای مدرن ایجاد کرد و رایانهها را قادر میسازد تا وظایفی از تشخیص اشیا تا درک صحنههای پیچیده را انجام دهند.
تکنیک های اصلی در بینایی کامپیوتر سنتی
آستانه گذاری:
این تکنیک در پردازش و تقسیم بندی تصویر اساسی است. این شامل تبدیل یک تصویر در مقیاس خاکستری به یک تصویر باینری است، جایی که پیکسل ها بر اساس مقدار آستانه به عنوان پیش زمینه یا پس زمینه علامت گذاری می شوند. به عنوان مثال، در یک برنامه اصلی، آستانه گذاری می تواند برای تشخیص یک شی از پس زمینه آن در یک تصویر سیاه و سفید استفاده شود.
تشخیص لبه:
در تشخیص ویژگی و تجزیه و تحلیل تصویر بسیار مهم است، الگوریتم های تشخیص لبه مانند آشکارساز لبه Canny مرزهای اشیاء را در یک تصویر شناسایی می کنند. با تشخیص ناپیوستگی در روشنایی، این الگوریتمها به درک شکلها و موقعیتهای اجسام مختلف در تصویر کمک میکنند و پایهای برای تجزیه و تحلیل پیشرفتهتر میسازند.
OpenCV
OpenCV (Open Source Computer Vision Library) یک بازیکن کلیدی در بینایی کامپیوتر است که از اواخر دهه 1990 بیش از 2500 الگوریتم بهینه شده را ارائه می دهد. سهولت استفاده و تطبیق پذیری آن در کارهایی مانند تشخیص چهره و نظارت بر ترافیک، آن را در دانشگاه و صنعت، به ویژه در برنامه های بلادرنگ، محبوب کرده است.
حوزه بینایی کامپیوتر با ظهور یادگیری عمیق به طور قابل توجهی تکامل یافته است و از روش های سنتی و مبتنی بر قوانین به سیستم های پیشرفته تر و سازگارتر تغییر می کند. تکنیک های قبلی، مانند آستانه گذاری و تشخیص لبه، محدودیت هایی در سناریوهای پیچیده داشتند. یادگیری عمیق، بهویژه شبکههای عصبی کانولوشنال (CNN)، با یادگیری مستقیم از دادهها بر این موارد غلبه میکند و امکان تشخیص و طبقهبندی دقیقتر و همهکارهتر تصویر را فراهم میکند.
این پیشرفت، با افزایش قدرت محاسباتی و مجموعه داده های بزرگ، منجر به پیشرفت های قابل توجهی در زمینه هایی مانند وسایل نقلیه خودران و تصویربرداری پزشکی شده است و یادگیری عمیق را به یک جنبه اساسی از بینایی رایانه مدرن تبدیل کرده است.
مدل های یادگیری عمیق:
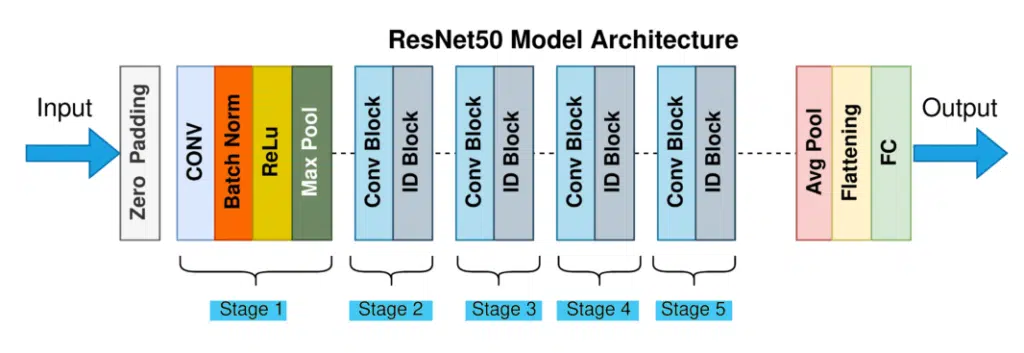
ResNet-50 برای طبقه بندی تصاویر
ResNet-50 گونه ای از مدل ResNet (شبکه باقیمانده) است که پیشرفتی در زمینه یادگیری عمیق برای بینایی کامپیوتر، به ویژه در وظایف طبقه بندی تصاویر بوده است. “50” در ResNet-50 به تعداد لایههای شبکه اشاره دارد – دارای 50 لایه عمیق است که در مقایسه با مدلهای قبلی افزایش قابل توجهی دارد.
ویژگی های کلیدی ResNet-50:
1. بلوک های باقیمانده: ایده اصلی پشت ResNet-50 استفاده آن از بلوک های باقی مانده است. این بلوک ها به مدل این امکان را می دهند که از یک یا چند لایه از طریق آنچه به عنوان “اتصالات پرش” یا “اتصالات میانبر” شناخته می شوند، عبور کند. این طرح به مشکل گرادیان ناپدید شدن میپردازد، یک مسئله رایج در شبکههای عمیق که در آن شیبها با انتشار پسانداز در لایهها کوچکتر و کوچکتر میشوند و آموزش شبکههای بسیار عمیق را دشوار میکند.
2. آموزش بهبود یافته: به لطف این بلوک های باقیمانده، ResNet-50 می تواند بسیار عمیق تر آموزش داده شود بدون اینکه از مشکل گرادیان ناپدید شدن رنج ببرد. این عمق شبکه را قادر میسازد تا ویژگیهای پیچیدهتری را در سطوح مختلف بیاموزد، که عاملی کلیدی در بهبود عملکرد آن در وظایف طبقهبندی تصویر است.
3. تطبیق پذیری و کارایی: ResNet-50 علیرغم عمقی که دارد از نظر منابع محاسباتی در مقایسه با سایر مدل های عمیق نسبتاً کارآمد است. دقت بسیار خوبی در معیارهای طبقه بندی تصاویر مختلف مانند ImageNet به دست می آورد و آن را به یک انتخاب محبوب در جامعه تحقیقاتی و صنعت تبدیل می کند.
4. برنامه های کاربردی: ResNet-50 به طور گسترده در برنامه های کاربردی مختلف در دنیای واقعی استفاده شده است. توانایی آن در طبقه بندی تصاویر به هزاران دسته، آن را برای کارهایی مانند تشخیص اشیا در وسایل نقلیه خودران، طبقه بندی محتوا در پلتفرم های رسانه های اجتماعی و کمک به روش های تشخیصی در مراقبت های بهداشتی با تجزیه و تحلیل تصاویر پزشکی مناسب می کند.
تاثیر بر بینایی کامپیوتر:
ResNet-50 به طور قابل توجهی در زمینه طبقه بندی تصاویر پیشرفت کرده است. معماری آن به عنوان پایه ای برای بسیاری از نوآوری های بعدی در یادگیری عمیق و بینایی کامپیوتر عمل می کند. ResNet-50 با فعال کردن آموزش شبکههای عصبی عمیقتر، امکانات جدیدی را در دقت و پیچیدگی وظایفی که سیستمهای بینایی کامپیوتری میتوانند انجام دهند، باز کرد.
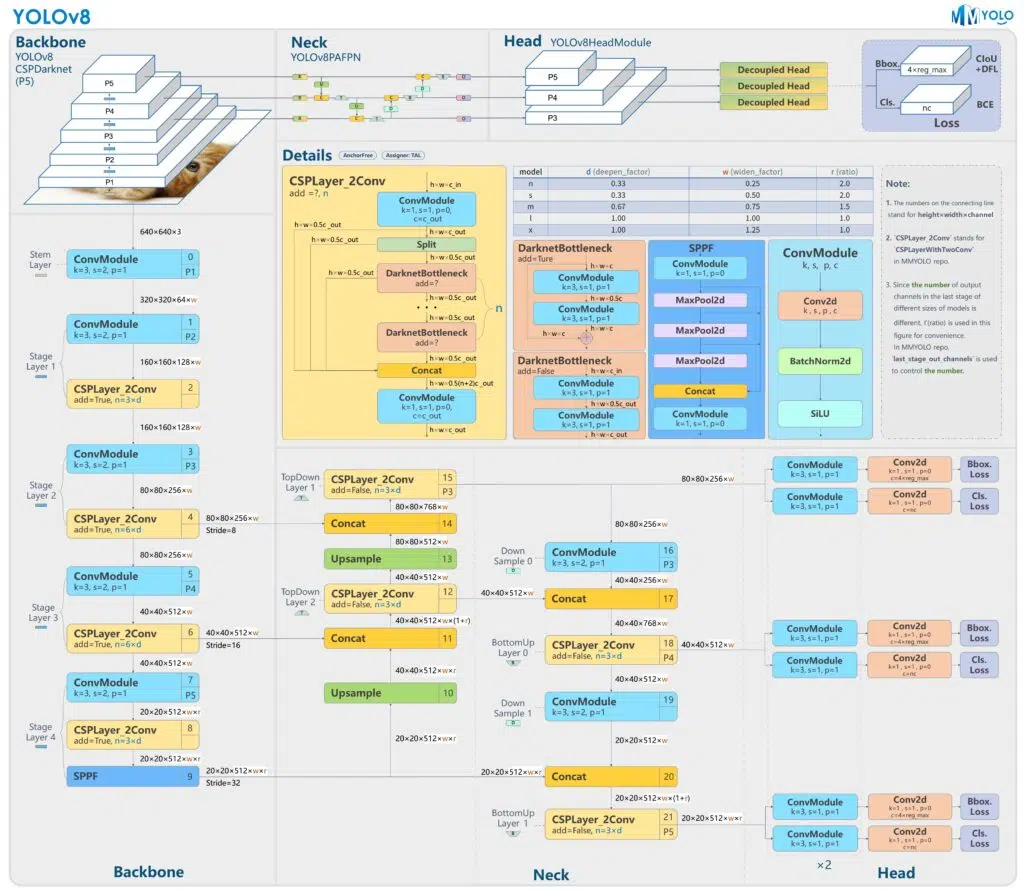
مدل YOLO (You Only Look Once)
مدل YOLO (You Only Look Once) یک رویکرد انقلابی در زمینه بینایی کامپیوتر، به ویژه برای وظایف تشخیص اشیا است. YOLO به دلیل سرعت و کارایی خود متمایز است و تشخیص شی در زمان واقعی را به واقعیت تبدیل می کند.
ویژگی های کلیدی YOLO
شبکه عصبی منفرد برای تشخیص: بر خلاف روشهای سنتی تشخیص اشیا که معمولاً شامل مراحل جداگانه برای تولید پیشنهاد های ناحیه و دسته بندی این نواحی است، YOLO از یک شبکه عصبی کانولوشنال (CNN) برای انجام هر دو به طور همزمان استفاده میکند. این رویکرد یکپارچه به آن اجازه می دهد تا تصاویر را در زمان واقعی پردازش کند.
سرعت و پردازش بیدرنگ: معماری YOLO به آن اجازه میدهد تصاویر را بسیار سریع پردازش کند، و آن را برای برنامههایی که نیاز به تشخیص بیدرنگ دارند، مانند نظارت تصویری و وسایل نقلیه خودران، مناسب میسازد.
درک متنی جهانی: YOLO در طول آموزش و آزمایش به کل تصویر نگاه می کند و به آن اجازه می دهد تا با زمینه یاد بگیرد و پیش بینی کند. این دیدگاه جهانی به کاهش مثبت کاذب در تشخیص اشیا کمک می کند.
نسخه تکامل: تکرارهای اخیر مانند YOLOv5 ،YOLOv6 ،YOLOv7 و آخرین YOLOv8، پیشرفت های قابل توجهی را ارائه کرده اند. این مدلهای جدیدتر بر اصلاح معماری با لایههای بیشتر و ویژگیهای پیشرفتهتر تمرکز میکنند و عملکرد آنها را در برنامههای مختلف دنیای واقعی افزایش میدهند.
تاثیر بر بینایی کامپیوتر
سهم YOLO در زمینه یادگیری عمیق بینایی کامپیوتر قابل توجه بوده است. توانایی آن برای انجام تشخیص اشیاء در زمان واقعی، دقیق و کارآمد، فرصتهای زیادی را برای کاربردهای عملی که قبلاً با سرعتهای تشخیص آهستهتر محدود شده بودند، باز کرده است. تکامل آن در طول زمان همچنین نشان دهنده پیشرفت و نوآوری سریع در زمینه یادگیری عمیق در بینایی کامپیوتر است.
کاربردهای دنیای واقعی YOLO
سیستمهای مدیریت و نظارت ترافیک: یک کاربرد واقعی مدل YOLO در حوزه مدیریت ترافیک و سیستمهای نظارت است. این نرم افزار توانایی مدل را برای پردازش داده های بصری در زمان واقعی نشان می دهد که یک نیاز حیاتی برای مدیریت و نظارت بر جریان ترافیک شهری است.
پیاده سازی در نظارت ترافیک: تشخیص خودرو و عابر پیاده – YOLO برای شناسایی و ردیابی وسایل نقلیه و عابران پیاده در زمان واقعی از طریق دوربین های ترافیکی استفاده می شود. توانایی آن برای پردازش سریع فیدهای ویدیویی امکان شناسایی فوری انواع مختلف وسایل نقلیه، عابران پیاده و حتی ناهنجاریهایی مانند پیادهروی را فراهم میکند.
تجزیه و تحلیل جریان ترافیک: با نظارت مداوم بر ترافیک، YOLO به تجزیه و تحلیل الگوهای ترافیک و تراکم کمک می کند. از این داده ها می توان برای بهینه سازی کنترل چراغ راهنمایی، کاهش ازدحام و بهبود جریان ترافیک استفاده کرد.
تشخیص تصادف و واکنش: این مدل می تواند تصادفات بالقوه یا رویدادهای غیرمعمول در جاده ها را تشخیص دهد. در صورت بروز حادثه، میتواند بلافاصله به مقامات مربوطه هشدار دهد و واکنش سریعتر اضطراری را ممکن میسازد.
اجرای قوانین راهنمایی و رانندگی: YOLO همچنین میتواند با شناسایی تخلفاتی مانند سرعت غیرمجاز، تغییر خطوط غیرقانونی یا روشن کردن چراغهای قرمز به اجرای قوانین راهنمایی و رانندگی کمک کند. سیستم های خودکار فروش بلیط می توانند با YOLO ادغام شوند تا رویه های اجرایی را ساده تر کنند.
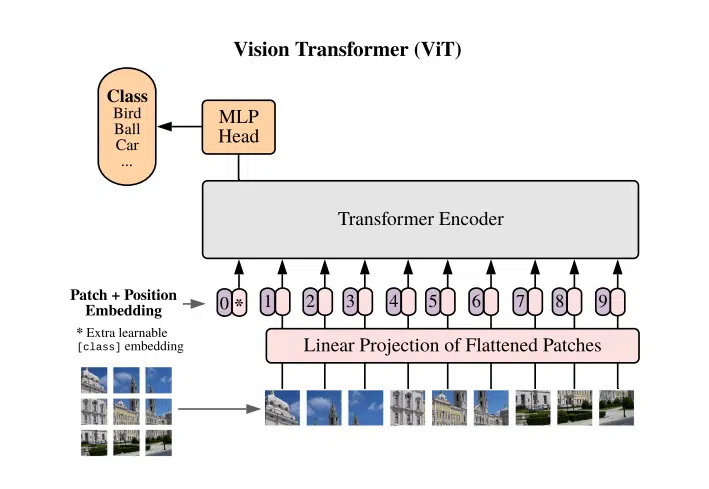
ترانسفورماتورهای بینایی
این مدل اصول ترانسفورماتورها را که در اصل برای پردازش زبان طبیعی طراحی شدهاند، برای طبقهبندی و تشخیص تصویر اعمال میکند. این شامل تقسیم یک تصویر به تکههای با اندازه ثابت، جاسازی این وصلهها، افزودن اطلاعات موقعیتی و سپس تغذیه آنها به یک رمزگذار ترانسفورماتور است.
این مدل از ترکیبی از شبکههای توجه چند سر و پرسپترونهای چندلایه در معماری خود برای پردازش این وصلههای تصویر و انجام طبقهبندی استفاده میکند.
ویژگی های کلیدی
پردازش تصویر مبتنی بر وصله (Patch-based Image Processing): ViT یک تصویر را به وصلهها تقسیم میکند و آنها را به صورت خطی جاسازی میکند و تصویر را به عنوان دنبالهای از وصلهها در نظر میگیرد.
جاسازی های موقعیتی (Positional Embeddings): برای حفظ رابطه فضایی قسمت های تصویر، جاسازی های موقعیتی به تعبیه های پچ اضافه می شود.
مکانیسم توجه چند سر (Multi-head Attention Mechanism): از یک شبکه توجه چند سر برای تمرکز بر مناطق بحرانی درون تصویر و درک روابط بین تکه های مختلف استفاده می کند.
عادی سازی لایه ها (Layer Normalization): این ویژگی با عادی سازی ورودی ها در سراسر لایه ها، تمرین پایدار را تضمین می کند.
سر پرسپترون چندلایه (Multilayer Perceptron Head (MLP)): مرحله نهایی مدل ViT، که در آن خروجی های رمزگذار ترانسفورماتور برای طبقه بندی پردازش می شود.
جاسازی کلاس (Class Embedding): ViT شامل یک جاسازی کلاس قابل یادگیری است که توانایی آن را برای طبقه بندی دقیق تصاویر افزایش می دهد.
تاثیر بر بینایی کامپیوتر
دقت و کارایی پیشرفته: مدلهای ViT پیشرفتهای قابلتوجهی در دقت و کارایی محاسباتی نسبت به CNNهای سنتی در طبقهبندی تصاویر نشان دادهاند.
سازگاری با وظایف مختلف: فراتر از طبقه بندی تصویر، ViT ها به طور موثر در تشخیص اشیا، تقسیم بندی تصویر و سایر وظایف پیچیده بینایی اعمال می شوند.
مقیاس پذیری: رویکرد مبتنی بر پچ و مکانیسم توجه، ViT را برای پردازش تصاویر بزرگ و پیچیده مقیاس پذیر می کند.
رویکرد نوآورانه: با اعمال معماری ترانسفورماتور بر روی تصاویر، ViT نشان دهنده یک تغییر پارادایم در نحوه درک و پردازش اطلاعات بصری مدل های یادگیری ماشین است.
Vision Transformer نشان دهنده پیشرفت قابل توجهی در زمینه بینایی کامپیوتر است و جایگزینی قدرتمند برای CNN های معمولی ارائه می دهد و راه را برای تکنیک های پیچیده تر تجزیه و تحلیل تصویر هموار می کند.
Vision Transformers (ViTs) به دلیل کارایی و دقت آنها در مدیریت داده های تصویر پیچیده به طور فزاینده ای در انواع برنامه های کاربردی دنیای واقعی در زمینه های مختلف استفاده می شود.
برنامه های کاربردی دنیای واقعی
طبقهبندی تصویر و تشخیص اشیا: ViTها در طبقهبندی تصاویر بسیار مؤثر هستند و با یادگیری الگوها و روابط پیچیده درون تصویر، تصاویر را به کلاسهای از پیش تعریفشده دستهبندی میکنند. در تشخیص اشیا، آنها نه تنها اشیاء را در یک تصویر طبقه بندی می کنند، بلکه موقعیت آنها را دقیقاً محلی می کنند. این باعث می شود آنها برای برنامه های کاربردی در رانندگی مستقل و نظارت مناسب باشند، جایی که تشخیص دقیق و موقعیت یابی اشیا بسیار مهم است.
تقسیمبندی تصویر: در تقسیمبندی تصویر، ViTها یک تصویر را به بخشها یا مناطق معنادار تقسیم میکنند. آنها در تشخیص جزئیات ریز دانه در یک تصویر و مشخص کردن دقیق مرزهای اشیا عالی هستند. این قابلیت به ویژه در تصویربرداری پزشکی ارزشمند است، جایی که تقسیم بندی دقیق می تواند به تشخیص بیماری ها و شرایط کمک کند.
تشخیص عمل: vit ها در تشخیص عمل برای درک و طبقه بندی اعمال انسان در ویدیوها استفاده می شود. قابلیت پردازش تصویر قوی آنها، آنها را در زمینه هایی مانند نظارت تصویری و تعامل انسان و رایانه مفید می کند.
مدلسازی تولیدی و وظایف چندوجهی: ViTها در مدلسازی تولیدی و وظایف چندوجهی، از جمله زمینهسازی بصری (پیوند دادن توضیحات متنی به مناطق تصویر مربوطه)، پاسخگویی به سؤالات بصری و استدلال بصری کاربرد دارند. این نشان دهنده تطبیق پذیری آنها در ادغام اطلاعات بصری و متنی برای تجزیه و تحلیل و تفسیر جامع است.
آموزش انتقالی: یکی از ویژگی های مهم ViT ها ظرفیت آنها برای انتقال یادگیری است. با استفاده از مدل های از پیش آموزش دیده روی مجموعه داده های بزرگ، ViT ها را می توان برای کارهای خاص با مجموعه داده های نسبتاً کوچک تنظیم کرد. این به طور قابل توجهی نیاز به داده های برچسب گذاری شده گسترده را کاهش می دهد و ViT ها را برای طیف گسترده ای از برنامه ها کاربردی می کند.
نظارت و بازرسی صنعتی: در یک کاربرد عملی، ViT از پیش آموزش دیده DINO در ربات Spot Boston Dynamics برای نظارت و بازرسی سایتهای صنعتی ادغام شد. این برنامه توانایی ViTs را برای خودکارسازی وظایفی مانند خواندن اندازهگیریها از فرآیندهای صنعتی و انجام اقدامات مبتنی بر دادهها، نشان دادن کاربرد آنها در پیچیده و واقعی نشان میدهد.





