
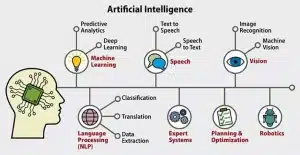
شاخههای هوش مصنوعی؛ تکنیکها، روشها و فرآیندهای AI

تا به حال، چندین بار درباره مفاهیم مختلفی از جمله یادگیری ماشینی، یادگیری عمیق، سیستمهای خبره، رباتیک، پردازش زبانهای طبیعی و مسائل دیگر صحبت کردیم.
تا به حال، چندین بار درباره مفاهیم مختلفی از جمله یادگیری ماشینی، یادگیری عمیق، سیستمهای خبره، رباتیک، پردازش زبانهای طبیعی و مسائل دیگر صحبت کردیم. اما این مفاهیم دقیقا چه هستند و چه ارتباطی با AI دارند؟ همانطور که گفتیم، هوش مصنوعی یک علم و مهندسی است. حالا با استفاده از تکنیکها، روشها یا فرآیندهایی که در ادامه راجع به آنها صحبت میکنیم، میتوان هوش مصنوعی Artificial Intelligence را برای حل مسائل دنیای واقعی بهکار برد. این تکنیکها شامل موارد زیر هستند:
یادگیری ماشینی ، شبکه عصبی و یادگیری عمیق ، پردازش زبانهای طبیعی ، مدلهای زبانی بزرگ ، رباتیک ، سیستمهای خبره ، منطق فازی ، دید ماشینی ، دید کامپیوتری ، برنامهریزی و بهینهسازی ، تشخیص گفتار و صدا ، علم داده ، رایانش شناختی ، داده کاوی
یادگیری ماشینی (Machine learning)
ماشین لرنینگ یا ML زیرشاخهای از ای آی است که بدون برنامهنویسی و با استفاده از الگوریتمها، میتوان ماشینها را به تفسیر، تحلیل و پردازش دادهها برای حل مسائل دنیای واقعی بهکار گرفت. در واقع این الگوریتمها خودشان الگوها را شناسایی کرده و بهجای گرفتن دستورات مستقیم برنامهنویسی، با پردازش دادهها و تجارب، نحوه پیشبینی کردن و پیشنهاددهی را یاد میگیرند. بنابراین، الگوریتمهای ML از دادههای تاریخی بهعنوان ورودی جهت پیشبینی مقادیر خروجی استفاده کرده و به مرور زمان خودشان را بهبود میدهند.
3 نوع الگوریتم یادگیری ماشینی وجود دارد:
- یادگیری تحت نظارت (Supervised Learning): مجموعه دادهها برچسبگذاری میشوند تا شناسایی و استفاده از الگوها برای برچسبگذاری مجموعه دادههای جدید مسیر شود.
- یادگیری نظارت نشده (Unsupervised Learning): مجموعه دادهها برچسبگذاری نشده و بر اساس شباهتها یا تفاوتهایشان مرتب میشوند.
- یادگیری تقویتی (Reinforcement Learning): مجموعه دادهها برچسبگذاری نشده، اما پس از انجام یک یا چندین عمل، به سیستم هوش مصنوعی فیدبک داده میشود.
از آنجایی که در دنیای امروز حجم و پیچیدگی دادههای تولیدی برای انسان بالاست، پتانسیل استفاده از ماشین لرنینگ نیز افزایش یافته است. از مهمترین کاربردهای یادگیری ماشینی که استفاده از آن از دهه 70 میلادی آغاز شد، میتوان پیشبینی وضعیت آب و هوا و تحلیل تصاویر پزشکی را نام برد.
شبکه عصبی (Neural Network) و یادگیری عمیق (Deep Learning)
موفقیت یادگیری ماشینی به شبکههای عصبی وابسته است. شبکه عصبی روشی در هوش مصنوعی است که نحوه پردازش دادهها بهگونهای الهامگرفتهشده از مغز انسان را به کامپیوترها آموزش میدهد. این نوع فرآیند یادگیری ماشینی که به آن یادگیری عمیق میگویند، از نودها یا نورونهای متصل به یکدیگر در ساختاری لایهای شبیه به مغز انسان استفاده میکنند.
به عبارت دیگر، شبکههای عصبی مدلهای ریاضی هستند که ساختار و عملکردشان مبتنی بر ارتباط بین نورونها در مغز انسان است و نحوه سیگنالدهی بین آنها را تقلید میکنند. برای درک بهتر، گروهی از رباتها را در نظر بگیرید که با همکاری یکدیگر، در تلاش برای حل یک پازل هستند و هر کدام از آنها، برای تشخیص یک شکل یا رنگ متفاوت در تکههای پازل طرحی شده است. حال این رباتها قابلیتهای خود را برای حل این پازل با یکدیگر ترکیب میکنند. یک شبکه عصبی، شبیه به این گروه از رباتهاست.
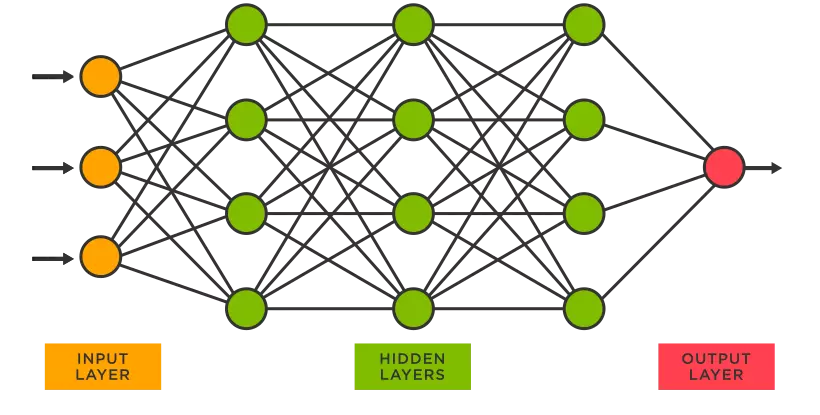
پس همانطور که مشخص است، دیپ لرنینگ یا DL زیرشاخهای پیچیده از یادگیری ماشینی است که ورودیها را در یک معماری شبکه عصبی الهامگرفتهشده از بیولوژیک موجودات زنده به اجرا درمیآورد. همانطور که در متصویر بالا مشاهده میکنید، شبکههای عصبی حاوی لایههای پنهانی هستند که از طریق آنها دادهها پردازش شده و اجازه «عمیق شدن» یادگیری را به ماشینها داده و در نتیجه، ارتباطات و خروجیهای مناسب را ایجاد میکنند. از یادگیری عمیق میتوان برای حل مسائل بسیار پیچیدهتر در دنیای واقعی استفاده کرد.
پردازش زبانهای طبیعی (Natural Language Processing)
پردازش زبانهای طبیعی یا NLP یک زیرشاخه بین رشتهای از رشتههای زبانشناسی و علوم کامپیوتر است. در این شاخه از علم، پردازش پایگاههای داده زبانهای طبیعی نظیر مجموعه گفتارها یا نوشتارها با استفاده از رویکردهای یادگیری ماشینی چه بهشکل مبتنی بر قانون چه احتمالی (بهصورت آماری یا در جدیدترین روش، بر اساس شبکههای عصبی)، انجام میگیرد. هدف این شاخه از ای آی، ساخت کامپیوتری توانمند در «درک» محتوای اسناد از جمله تفاوتهای ظریف زمینهای در زبانهاست.
از جمله کاربردهای NLP را میتوان در شبکه اجتماعی توییتر جهت فیلتر کردن گفتارهای خلاف قوانین در توییتها و در شرکت آمازون در راستای فهم نقدهای مشتریان و بهبود تجربه کاربری مشاهده کرد.
مدلهای زبانی بزرگ (Larg Language Models)
مدل زبانی بزرگ یا LLM نوعی الگوریتم هوش مصنوعی است که از تکنیکهای یادگیری عمیق، یا بهطور دقیقتر، از یادگیری ماشینی نظارت نشده (Unsupervised Learning) و مجموعه دادههای بسیار بزرگ برای درک، خلاصه کردن، تولید و پیشبینی محتوای جدید استفاده میکند. اصطلاح هوش مصنوعی مولد (Generative AI) نیز با LLMها رابطه نزدیکی دارد که از آن برای تولید محتوای متنمحور استفاده میشود.
زبان بهخاطر ایجاد کلمات، معانی و دستور زبان لازم برای انتقال ایدهها و مفاهیم، در قلب روابط انسانی قرار دارد. در دنیای AI، یک مدل زبانی با ایجاد پایههای ارتباط و تولید مفاهیم جدید، دارای هدف مشابهی است.
اولین مدل زبانی ساختهشده در تاریخ به توسعه مدل ELIZA در سال 1966 توس پروفسور دانشگاه MIT برمیگردد. از مدلهای زبانی در اپلیکیشنهای پردازش زبانهای طبیعی (NLP) استفاده میشود که کاربر یک کوئری را در یک زبان طبیعی وارد کرده و نتیجه آن تولید میشود. GPT-3.5 که ChatGPT بر اساس آن کار میکند، یکی دیگر از معروفترین مدلهای زبانی بزرگ است. GPT-4 بزرگترین LLM حال حاضر شناخته میشود. گوگل بارد نیز از مدل زبانی LaMDA استفاده میکند که در جایگاه دوم بزرگترین LLMها قرار دارد.
دید کامپیوتری (Computer Vision)
دید کامپیوتری یا کامپیوتر ویژن یکی از مهمترین زیرشاخههای هوش مصنوعی و مهندسی کامپیوتر است که به سیستمهای کامپیوتری اجازه میدهد اطلاعات معنادار را از دادههای بصری نظیر ویدیو و تصویر استخراج کرده و به پردازش، تحلیل، انجام اقدامات مناسب و پیشنهاددهی بر اساس آنها بپردازند.

این رشته نیز از مدلهای یادگیری ماشینی جهت شناسایی و طبقهبندی اشیاء در ویدیوها و تصاویر دیجیتالی استفاده کرده و با تحلیل و تفسیر دنیای مجازی، به شبیهسازی نحوه درک و دید ما از محیط اطراف میپردازد. در واقع، کامپیوتر ویژن علمی است که به درک پیچیدگی سیستم بینایی انسان و آموزش سیستمهای کامپیوتری برای تفسیر و درک بالای تصاویر و ویدیوهای دیجیتال کمک میکند.
دید ماشینی (Machine Vision)
دید ماشینی یا ماشین ویژن یعنی توانایی دیدن در یک کامپیوتر؛ حوزهای از یادگیری ماشینی که از دوربین برای دریافت اطلاعات بصری محیط پیرامون استفاده کرده و سپس با استفاده از ترکیبی از سخت افزارها و نرم افزارها، تصاویر را پردازش و اطلاعات را برای استفاده در برنامههای مختلف آماده میکند. به عبارتی میتوان گفت که دید ماشینی، ترکیبی از فناوریها، محصولات سخت افزاری و نرم افزاری، سیستمهای یکپارچه، اقدامات، روشها و تخصصها از جمله دوربین، تبدیل آنالوگ به دیجیتال (ADC) و پردازش سیگنال دیجیتال (DSP) است. در آخر، نتیجه نهایی وارد یک کامپیوتر یا کنترلر ربات میشود.
دید ماشینی بهعنوان یک رشته مهندسی سیستمها را میتوان از دید کامپیوتری که نوعی علم کامپیوتر است، جدا دانست. این رشته درصدد یکپارچه کردن فناوریهای فعلی به روشهای جدید و استفاده از آنها برای حل مسائل دنیای واقعی است. پیچیدگی دید ماشینی مشابه تشخیص صدا (Voice Recognition) است.
برخی از منابع، دیدی ماشینی را یک فناوری جداگانه میدانند که با استفاده از علم اپتیک (بهعنوان شاخهای از فیزیک) به دریافت تصاویر میپردازد. در این حالت، خصیصههای خاص یک تصویر پردازش، تحلیل و اندازهگیری میشود. مثلا، یک برنامه مبتنی بر دید ماشینی بهعنوان بخشی از یک سیستم تولیدی را میتوان برای تحلیل ویژگیهای خاص یک قسمت در حال تولید در یک خط مونتاژ استفاده کرد.
برنامهریزی و بهینهسازی (Planning and Optimization)
برنامهریزی و بهینهسازی خودکار، پایه زیربنایی ای آی است که تحقق استراتژیها یا توالی اقدامات، عموما برای اجرا توسط عاملهای هوشمند، رباتهای خودمختار و وسایل بدون دخالت انسان را شامل میشود. بر خلاف مسائل کنترل و طبقهبندی کلاسیک، راهحلهای این شاخه از AI پیچیدهتر است و باید در فضای چند بعدی کشف و بهینهسازی شود. برنامهریزی نیز به نظریه تصمیم مربوط میشود.
در محیطهای شناختهشده دارای مدلهای در دسترس، برنامهریزی را میتوان بهصورت آفلاین نیز انجام داد و راهحلها را پیش از اجرا پیدا و ارزیابی کرد. اما در محیطهای پویای ناشناخته، استراتژی مناسب معمولا باید بهصورت آنلاین بازنگری شود. علاوه بر این، راهحلها عموما از همان فرایندهای آزمون و خطای تکرارشوندهای که در هوش مصنوعی دیده میشود برای حل مسائل استفاده میکنند. این موارد شامل برنامهنویسی پویا (Dynamic Programming)، یادگیری تقویتی (Reinforcement Learning) و بهینهسازی ترکیبیاتی (Combinatorial Optimization) هستند.
تشخیص گفتار و صدا (Speech and Voice Recognition)
تشخیص گفتار (Speech Recognition) یا Speech-to-text نیز مشابه بسیاری از شاخههای هوش مصنوعی که تا اینجا گفتیم، یک زیرشاخه بین رشتهای از علوم کامپیوتر و زبانشناسی رایانشی (Computational Linguistic) است که به توسعه متدولوژیها و فناریهای فراهمکننده قابلیت تشخیص و ترجمه زبان گفتار به متن توسط کامپیوترها میپردازد.
بنابراین میتوان گفت که تشخیص گفتار، توانایی یک ماشین یا برنامه در شناسایی کلمات گفتهشده و سپس تبدیل آنها به متن قابل خواندن است. نرم افزارهای ابتدایی تشخیص گفتار دارای دایره لغات پایین بوده و تنها کلمات و اصطلاحاتی که بهصورت کاملا شفاف و مشخص بیان شوند را تشخیص میدهند. اما نرم افزارهای پیشرفتهتر قادر به کار با گفتار طبیعی، لهجههای مختلف و زبانهای متعدد هستند.
تشخیص گفتار از طیف گستردهای از تحقیقات علوم کامپیوتر، زبانشناسی و مهندسی کامپیوتر استفاده میکند. بسیاری از برنامههای مبتنی بر متن و دستگاههای مدرن و امروزی دارای عملکردهای تشخیص گفتار در خود بوده و کار کردن با یک دستگاه را بسیار سادهتر کردهاند.
اما تشخیص صدا (Voice Recognition) یا Speaker Recognition توانایی یک ماشین یا برنامه در دریافت و تفسیر املاء یا درک و انجام فرمانهای گفتاری است. سیری اپل و الکسای آمازون از جمله دستیارهای صوتی استفادهکننده از شاخه تشخیص صدا در AI هستند.
تشخیص صدا میتواند با استفاده از برنامههای نرم افزاری تشخیص گفتار خودکار (ASR)، صداهای مختلف را شناسایی و از یکدیگر متمایز کند. برخی از برنامههای ASR نیازمند آموزش اولیه جهت شناسایی صدا و تبدیل دقیقتر گفتار به متن هستند.
با اینکه افراد عموما تشخیص صدا و تشخیص گفتار را یکی دانسته و این دو عبارت را بهجای یکدیگر استفاده میکنند، اما باید دقت داشته باشید که دارای تفاوتهایی هستند. تشخیص صدا، گوینده را شناسایی کرده و تشخیص گفتار، سخن گفتهشده را ارزیابی میکند. به عبارت دیگر:
- تشخیص گفتار برای شناسایی کلمات یک زبان گفتهشده استفاده میشود.
- تشخیص صدا یک فناوری بیومتریک برای شناسایی صدای افراد است.
رایانش شناختی (Cognitive Computing)
رایانش شناختی اصطلاحی است که برای توصیف سیستمهای هوش مصنوعی شبیهساز افکار انسان جهت افزودن قدرت شناختی بهکار میرود. شناخت انسانی شامل تحلیل لحظهای محیط دنیای واقعی، زمینه، نیت و متغیرهای بسیار دیگر است که توانایی فرد در حل مسائل را مشخص میکند.
در حالت کلی، از رایانش شناختی برای کمک به انسان در فرایندهای تصمیمگیری استفاده میشود. Artificial Intelligence برای حل مسائل یا شناسایی الگوها در مجموعه دادههای بزرگ، به الگوریتمها متکی است، اما سیستمهای رایانش شناختی هدف والاتری در ساخت الگوریتمهایی دارند که به تقلید از فرآیند استدلال مغز انسان جهت حل مسائل در حین تغییر آنها و داده میپردازند.
علم داده (Data Science)
علم داده یا دیتا ساینس شاخهای است که برای آشکارسازی بینشهای عملی پنهان در دادههای یک سازمان، ریاضیات و آمار، برنامهنویسی تخصصی، تحلیلهای پیشرفته، ای آی و ماشین لرنینگ را با تخصص موضوعی خاص ترکیب میکند. از این بینشها میتوان برای هدایت تصمیمگیری و برنامهریزی استراتژیک استفاده کرد.
متخصصان علم داده برای تولید سیستمهای AI جهت انجام وظایفی که معمولا به هوش انسانی نیاز دارند، الگوریتمهای یادگیری ماشینی را بر اعداد، متن، تصاویر، ویدئو، صدا و دیگر موارد اعمال میکنند. در عوض، این سیستمها نیز بینشی را فراهم میکنند که تحلیلگران و کاربران تجاری قادر به تفسیر آنها به ارزش ملموس کسبوکار هستند.
داده کاوی (Data Mining)
داده کاوی یا دیتا ماینینگ شاخه دیگری از علم است که برای تحلیل مجموعه دادههای بزرگ جهت کشف اطلاعات سودمند، آمار و هوش مصنوعی را با یکدیگر ترکیب میکند.
دیتا ماینینگ بخش کلیدی تجربه و تحلیل داده و یکی از رشتههای اصلی در علم داده است که از تکنیکهای تحلیل پیشرفته برای یافتن اطلاعات در مجموعه دادهها استفاده میکند. در سطح جزئیتر، داده کاوی گامی در فرآیند کشف دانش در دیتابیسها (KDD) است. KDD متدولوژی در دیتا ساینس است که برای جمعآوری، پردازش و تحلیل دادهها بهکار میرود. گاهی اوقات اصطلاحات داده کاوی و کشف دانش در پایگاههای داده بهجای یکدیگر استفاده میشوند، اما باید بینشان تفاوت قائل شد.
عناصر اصلی دیتا ماینینگ، یادگیری ماشینی و تحلیل آماری هستند که در کنار انجام وظایف مدیریت داده برای آمادهسازی دادهها جهت تحلیل، استفاده میشوند. ترکیب الگوریتمهای ماشین لرنینگ و ابزارهای هوش مصنوعی باعث خودکارسازی این فرآیند و سادهتر شدن کاوش در مجموعه دادههای حجیم نظیر دیتابیسهای مشتری، سوابق تراکنشی و فایلهای ورود سرورهای وب، اپلیکیشنهای موبایل و سنسورها شدهاند.





